MCP
什么是MCP
MCP 在百科的词条如下:
模型上下文协议(Model Context Protocol,MCP),是由 Anthropic 推出的开源协议,旨在实现大语言模型与外部数据源和工具的集成,用来在大模型和数据源之间建立安全双向的连接 。
MCP 起源于 2024 年 11 月 25 日 Anthropic 发布的文章:Introducing the Model Context Protocol。
MCP (Model Context Protocol,模型上下文协议)定义了应用程序和 AI 模型之间交换上下文信息的方式。这使得开发者能够以一致的方式将各种数据源、工具和功能连接到 AI 模型(一个中间协议层),就像 USB-C 让不同设备能够通过相同的接口连接一样。MCP 的目标是创建一个通用标准,使 AI 应用程序的开发和集成变得更加简单和统一。
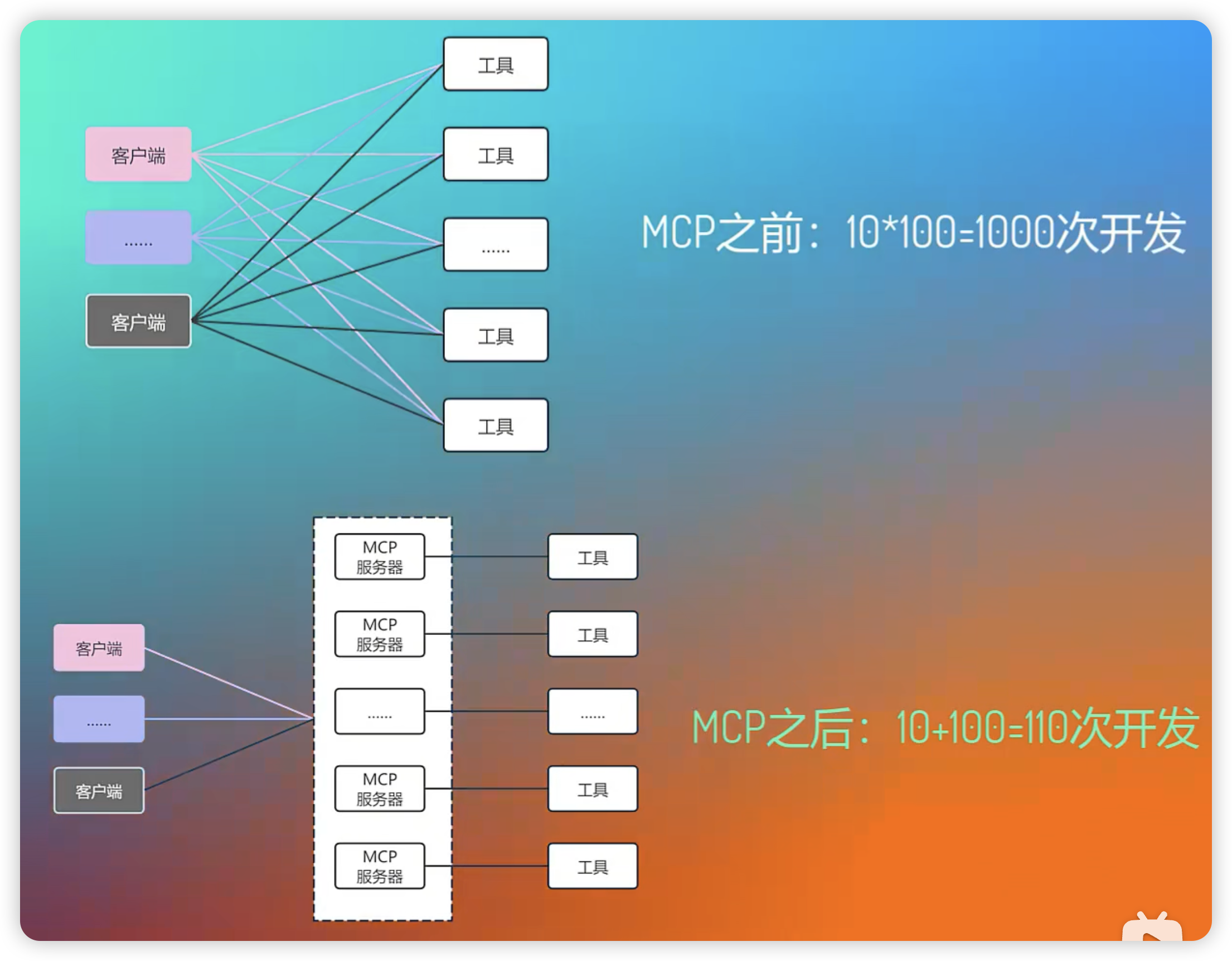
-
没有 MCP 时,每接入一个工具,都需要客户端进行适配;
-
有了 MCP 后,只需要按照协议标准,客户端无需进行额外的适配,就可以接入工具;
- 工作量不会消失,只会转移,实质是把适配的工作,放在了服务提供方,要求服务提供方在提供服务时,额外提供一份"说明书"
有了 MCP 后,模型调用 API ,从原来混乱无管理的状态,变成了简单规整的状态。
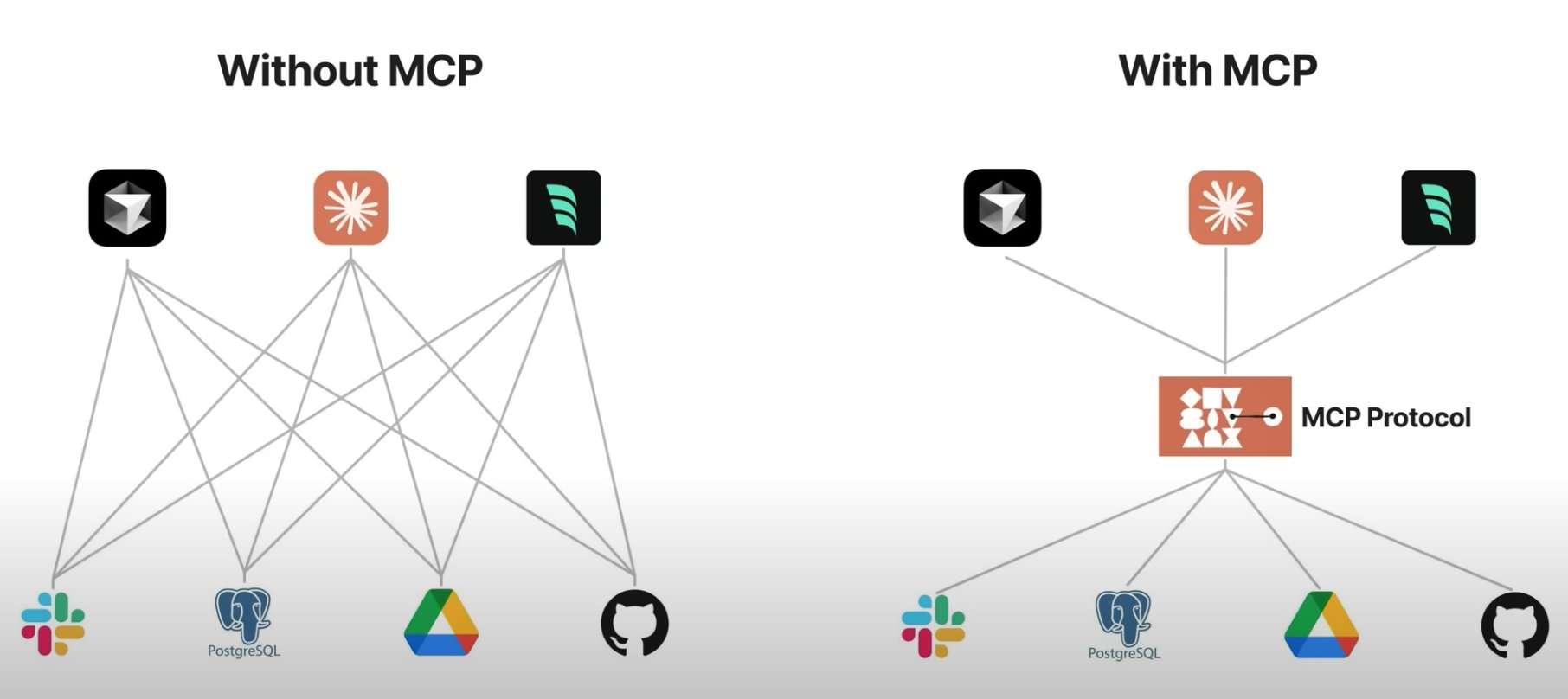
MCP 使用
-
配置
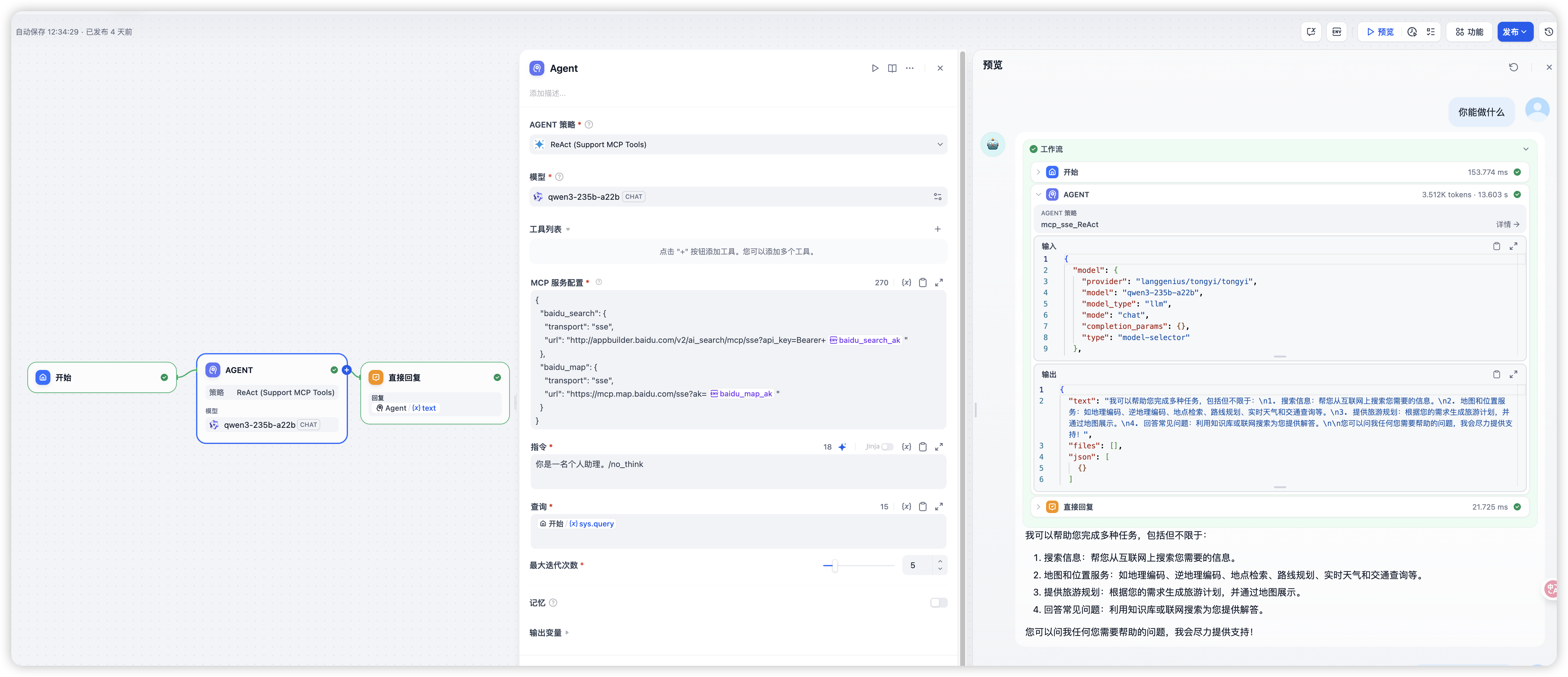
- 在 dify 上使用 MCP 很简单,首先选取支持 MCP 的策略,然后配置上 MCP 服务器,就可以使用了。
- 我这里配置了两个 MCP 服务器,一个是百度新闻搜索,一个是百度地图。
-
问能做什么
-
Agent 调用 MCP 服务器,知道了自己有两块能力,一个是联网搜索,一个地图能力,地图这里又进行了细分。
-
-
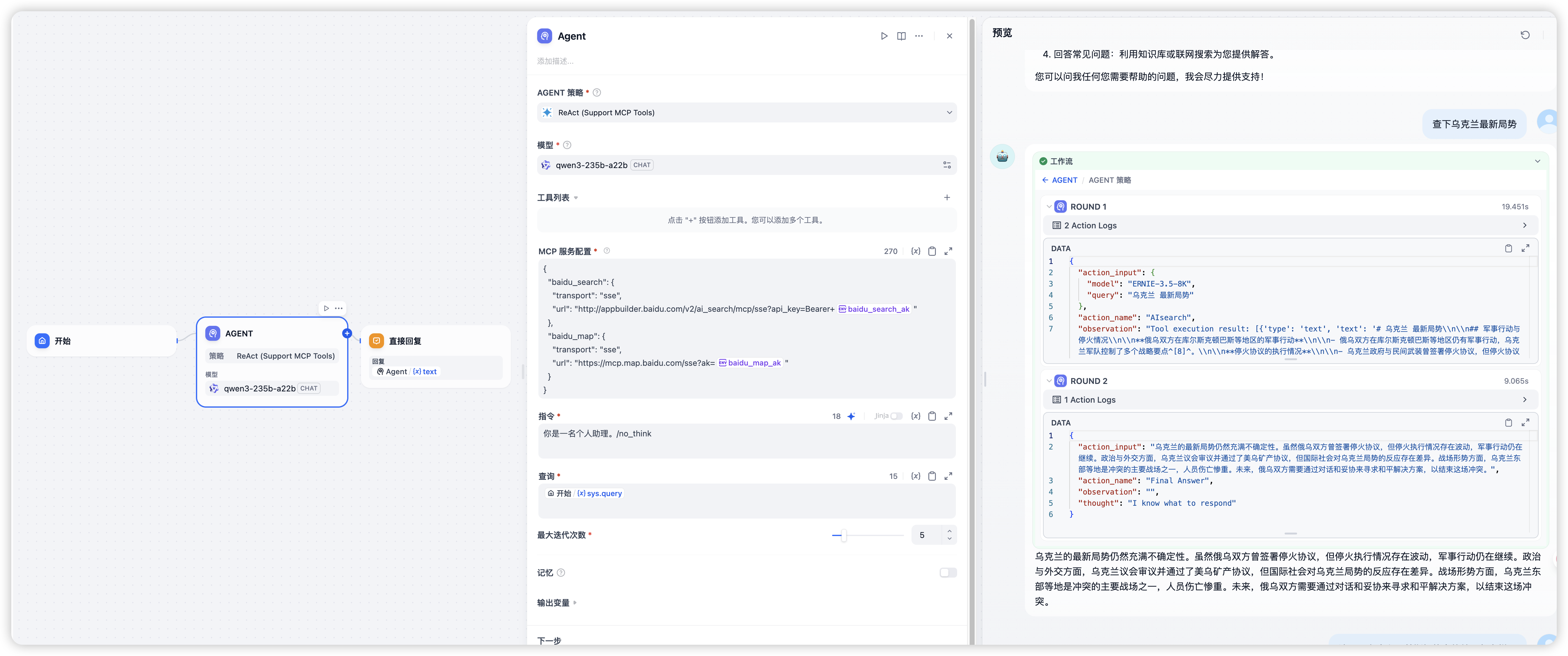
问乌克兰局势
-
可以看到,这里调用了 AIsearch 能力,查到了一些新闻,后进行了汇总
-
-
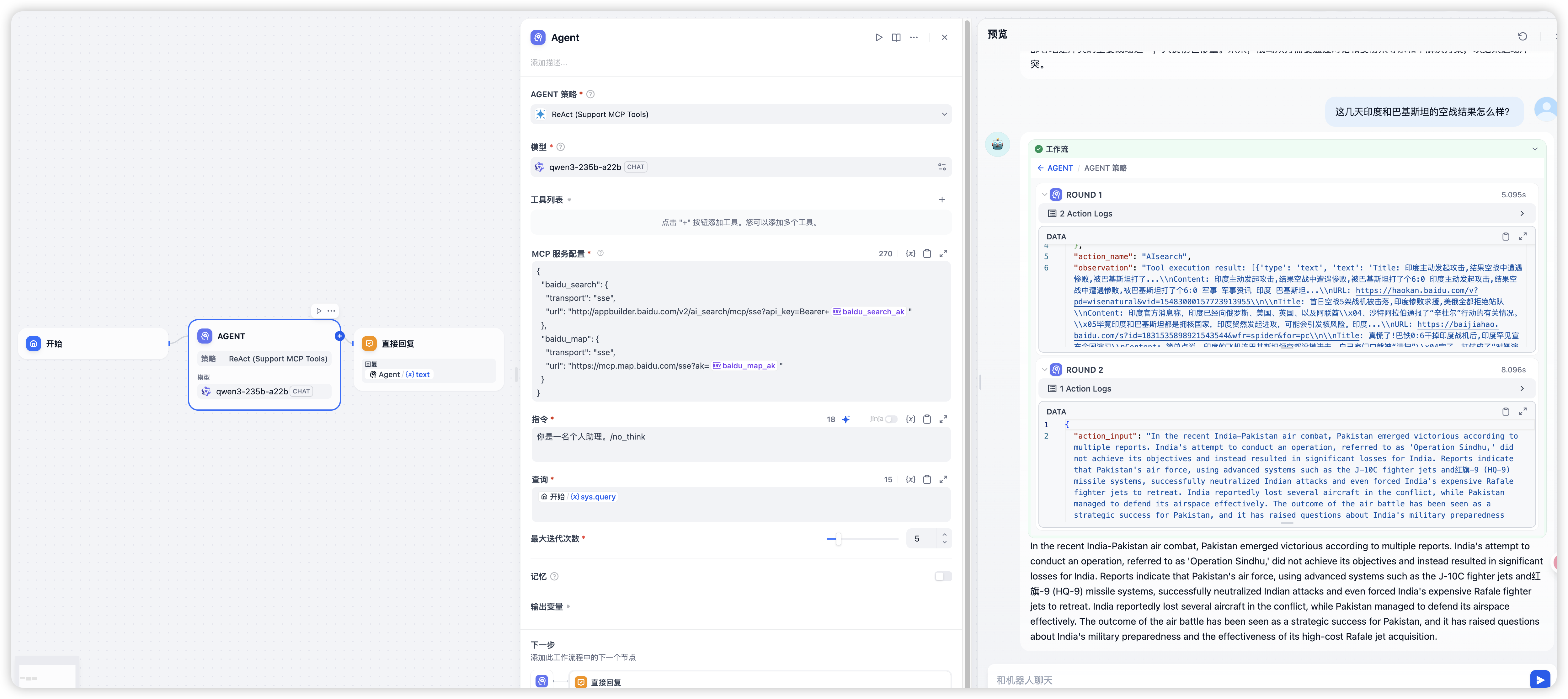
问印巴冲突
-
俄乌冲突时间比较长了,可能有人怀疑是模型本身的能力,那就问下最新的印巴冲突,毕竟这两天出现的空战还是首次。
-
这里就能看出,莫名其妙给了英文的回答,也就是模型能力不好的话,MCP 结果就很差。
-
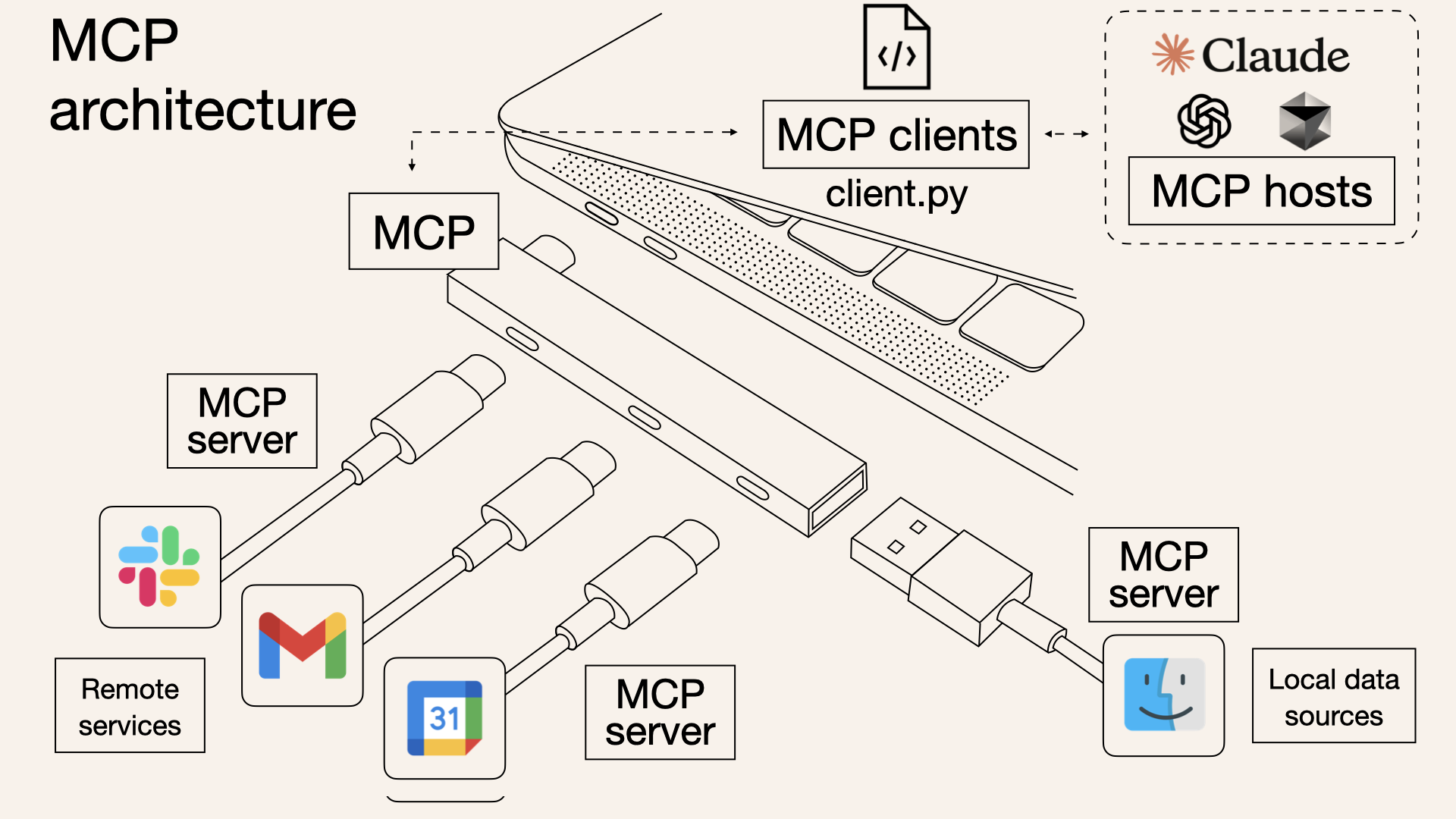
MCP 架构
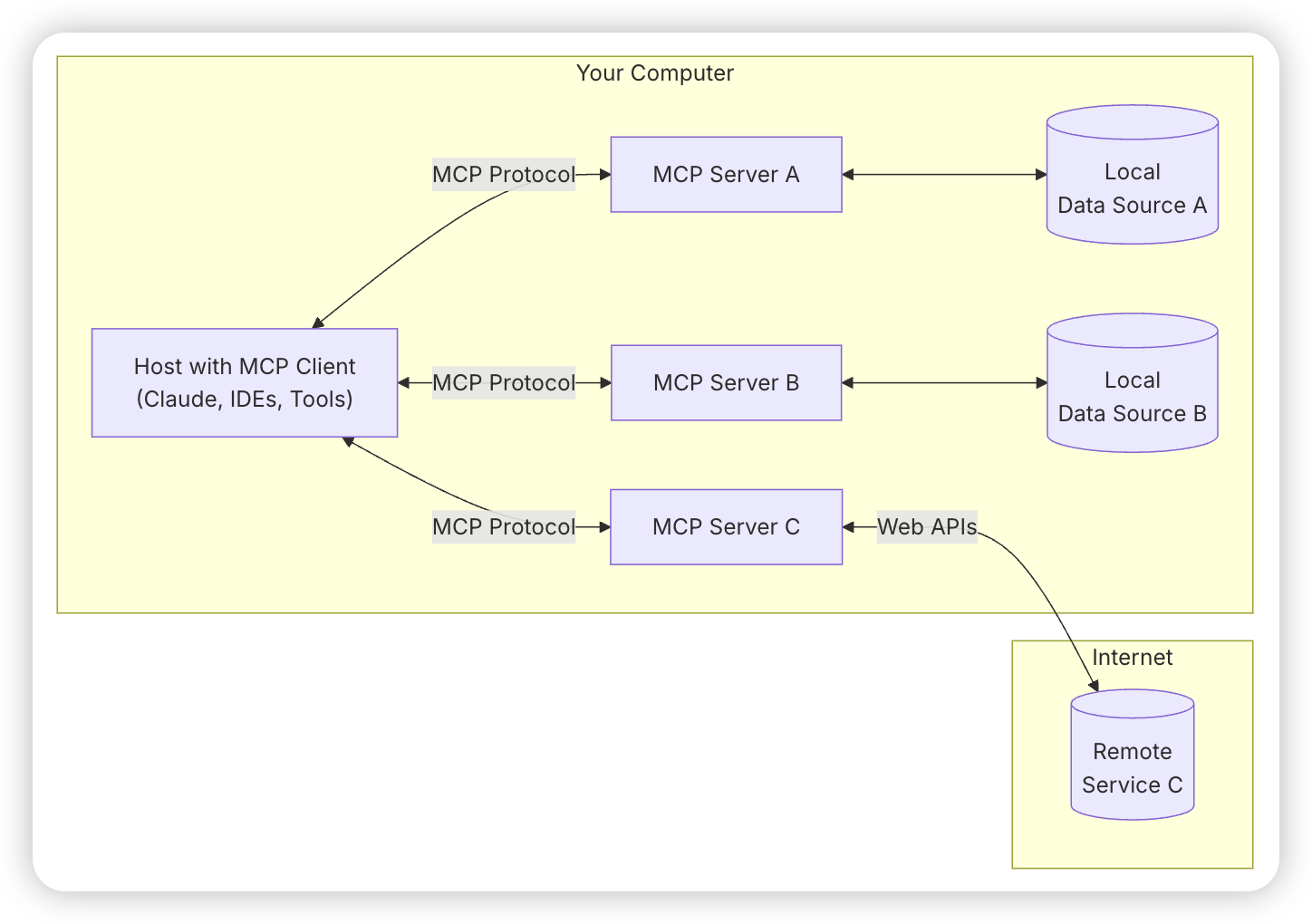
上图是官网中 MCP 的总体架构图,包含以下内容:
- MCP Hosts: 想要通过 MCP 访问数据的程序,如 Claude Desktop、IDE 或 AI 工具
- MCP Clients: 与服务器保持 1:1 连接的协议客户端
- MCP Servers: 轻量级程序,每个通过标准化的模型上下文协议暴露特定功能
- Local Data Sources: 您的计算机文件、数据库和服务,MCP 服务器可以安全访问
- Remote Services: 可通过互联网(例如通过 API)访问的外部系统,MCP 服务器可以连接
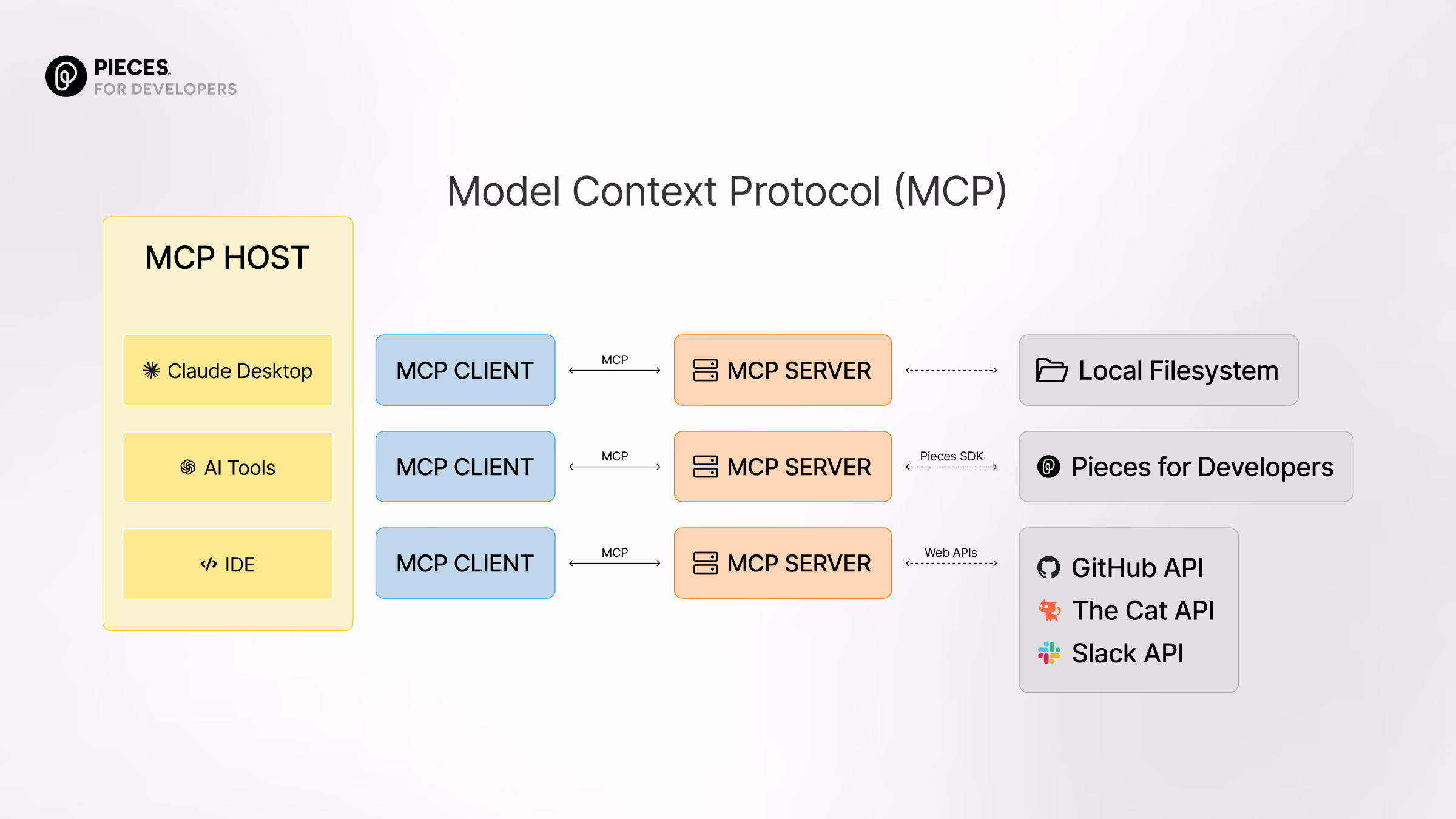
MCP 调用链路
使用 MCP 的流程如下: 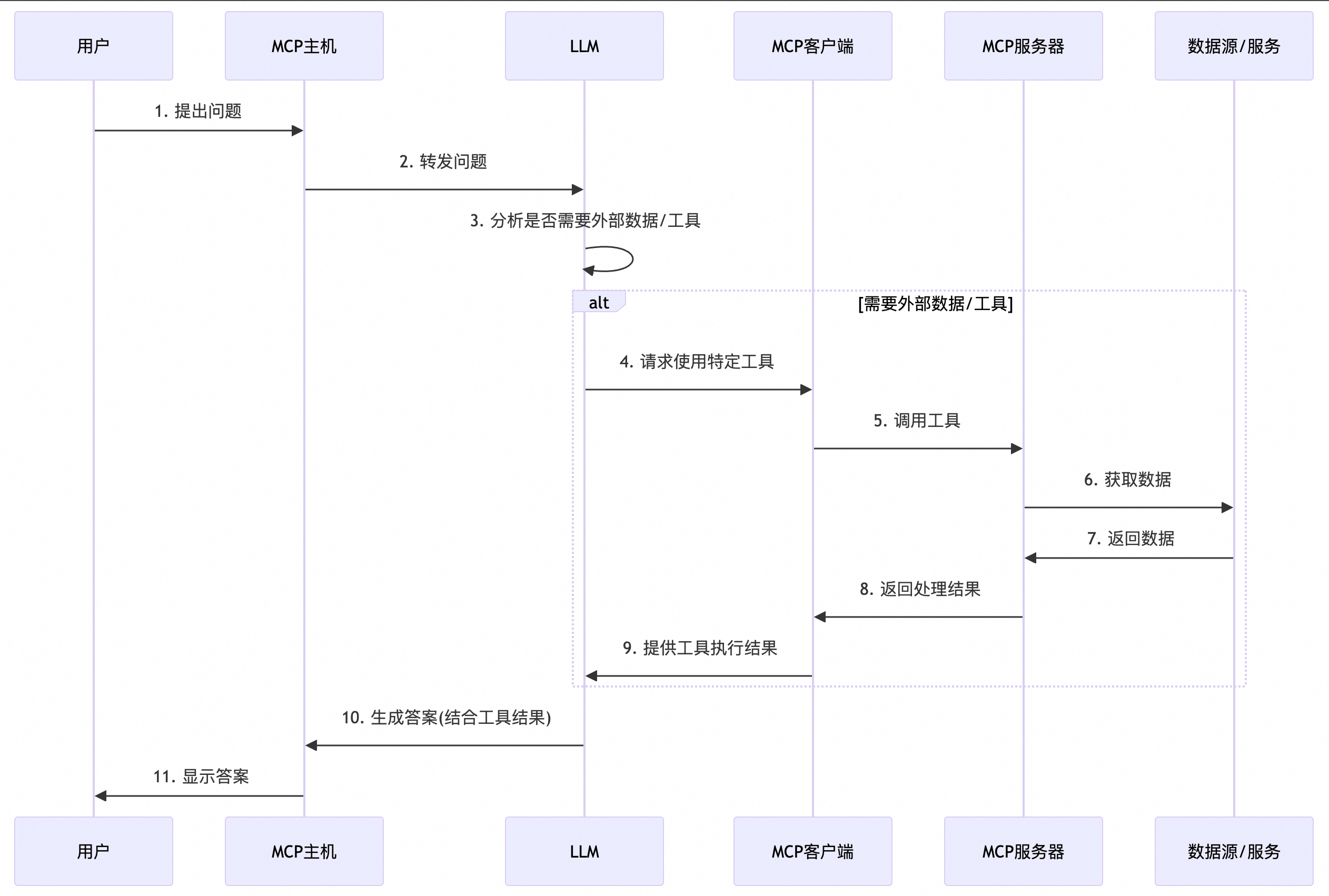
上面的资料,就是正确却用处不大的”假教材“,下面,真正的课程,正式开始。
大模型认知
磨刀不误砍柴工,想真正理解模型知识,首先需要理解模型最基础的概念。
跳过基础概念,直接讲深层次的东西,”5min 教会你 xxx“,看似捷径,实质都是歪门邪道。
首先,需要拉齐下对 AI 的认知。
现在我们说的大模型,一般都是指 LLM——大语言模型。
LLM——大"语言"模型
无论是 ChatGPT,还是 DeepSeek,还是 QWen2.5、Qwq、还是最近的 QWen3,都是大语言模型。这里需要突出的是,语言。
大语言模型(英语:Large Language Model,简称LLM)是指使用大量文本数据训练的深度学习模型,使得该模型可以生成自然语言文本或理解语言文本的含义。这些模型可以通过在庞大的数据集上进行训练来提供有关各种主题的深入知识和语言生产 [1]。其核心思想是通过大规模的无监督训练学习自然语言的模式和结构,在一定程度上模拟人类的语言认知和生成过程。

这里先输出一个“暴论”:
大语言模型,并不会“思考”,其本质更类似于“数据库查询”,它唯一能做的事情,是根据输入的文本,进行“检索”,最后输出相关性最高的文本。
大家可能不认同这一暴论,理由如下:
- 大模型会思考,DeepSeek R1 就有思考过程,最新的 QWen3 全系列都有思考模式。
- 大模型有 Agent 模式,它就是思考。
- 大模型能联网搜索。
- 刚讲了 MCP,让大模型“长出了手脚”,它能调 MCP 工具。
- 大模型能 xxxx
这些问题会在之后知识中得到解答,我们先继续学习。
目前主流的大语言模型,都是 GPT 模型。
GPT
生成式预训练变换器(Generative Pre-trained Transformer,GPT),是一个组合词汇,拆分开就是"生成式"、“预训练”、“变换器”。

- Pre-trained:这里"预训练"最容易理解,它很直白,就是提前训练过的意思,训练的结果就是我们常说的 32B、7B 这些 xxB,他们代表的是模型的参数,预训练就是确定这些参数的过程;
-
Transformer:这里其实不适合翻译成"变换器",它是指一种深度学习模型,最初由 Google 在 2017 年提出,其核心思想是通过自注意力机制(Self-Attention Mechanism)来捕捉序列中各元素之间的关系,从而实现对输入数据的高效处理。
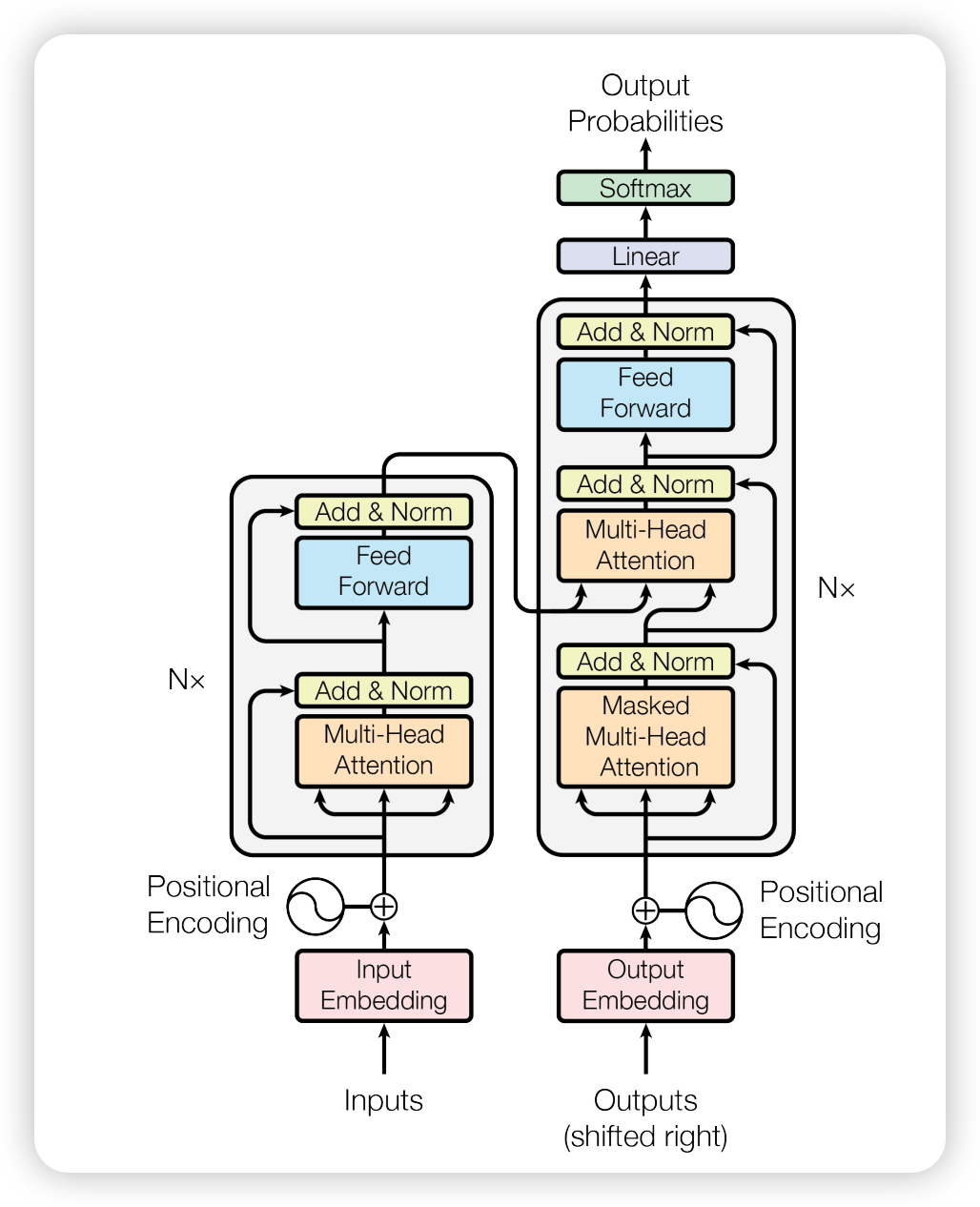
-
Generative:生成式,也就是产生新的。
除了生成式,人工智能解决的更多是分类(Classification)问题,也就是从有限的选项中做选择。比如垃圾邮件检测、图像识别、商品排序等,类似于我们考试中的客观题。
但生成式,就必须创造性回答,并不是在已有答案中选择最好的,而是要不断“生成”,还要确定是否答完了,拥有无限可能,类似于我们考试中的主观题。
既然对于考试而言,主观题比客观题更难、分值更高,那么在人工智能领域,生成式也自然更难。李宏毅老师说,生成式人工智能是机器产生复杂而有结构的物件,比如文章、影像、语音等。而什么是“复杂”呢?所谓复杂,就是几乎无法穷举。
什么叫几乎不可穷举呢?我们回过头来看垃圾邮件检测,结果就是 True/False;图像识别,结果就是各种物品、动植物、人等;商品排序,也就是在几万几十万的候选里面去做排序。这些都是在确定的候选集里面去做选择,也就是可穷举。而假设我们现在要写 100 字的作文,标题叫《我爱我的祖国》,会有多少种可能性呢?常用汉字有 3500 个,我们假设最最最常用的有 1000 个,那么 100 字的作文就是 1000 × 1000 × 1000 × … × 1000 = 1000^100 = 10^300 种可能,与之相对应的是宇宙中的粒子有 10^80 个。生成式就是从这近乎无穷的组合中找到一组比较好的组合。
ChatGPT
ChatGPT 是 GPT 的一种实现。拿”千禾零添加酱油“举例,GPT 就相当于酱油,符合这种定义的都是酱油;像”千禾零添加“是一种品牌,"ChatGPT"跟”千禾零添加酱油“一样,是一个产品。
ChatGPT 这种大语言模型本质上也是一个函数,只不过这个函数有上亿个甚至数十亿个参数。
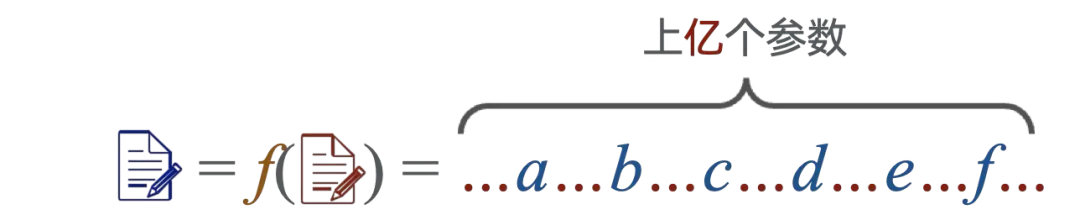
ChatGPT 的突然大火,让大语言模型被高度关注,之后的大语言模型如雨后春笋一样涌现出来。
和 ChatGPT 一样的大语言模型并不是根据问题直接在无数种可能中预测出正确结果,而是只预测后面一个字,完成文字接龙。
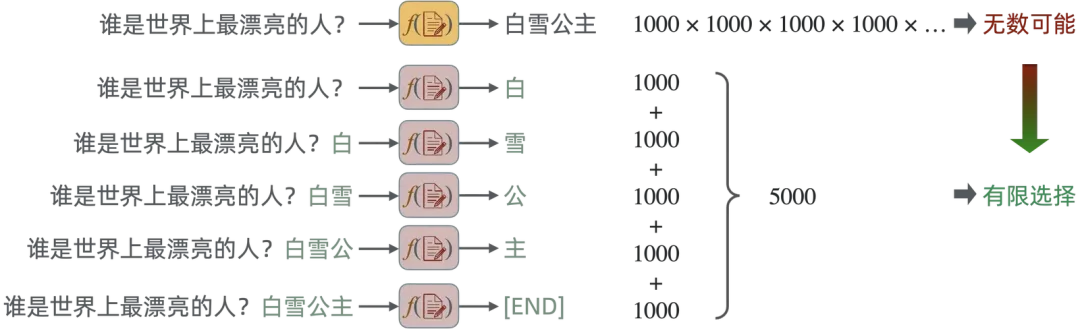
这就把一个乘法运算变成了加法运算,计算量就瞬间可控了。也就是巧妙地用分类策略解决了生成式问题。
而所谓的"预测",实际上是一系列复杂的数学运算,算出的结果是不同文字的"可能性",也就是概率,最终选取概率最高的词,就是返回的词。
有很多种方法都能计算下一个词,现在最先进的计算方法,就是 Transformer 架构。
Transformer
一只会说漂亮话的鹦鹉,它真的会”说话“吗?
2017 年Google发了划时代的论文 《Attention Is All You Need》。这篇论文以语言翻译为例,展示了如何用注意力机制,搭建起深度学习模型。模型本质是数学运算,可以把它理解成一个函数——将原始输入,和之前所有的输出,都作为入参,传给这个函数,然后函数会算出下一个词,然后再重复这个过程,直到所有的运算都完成。
- Transformer 翻译示意图
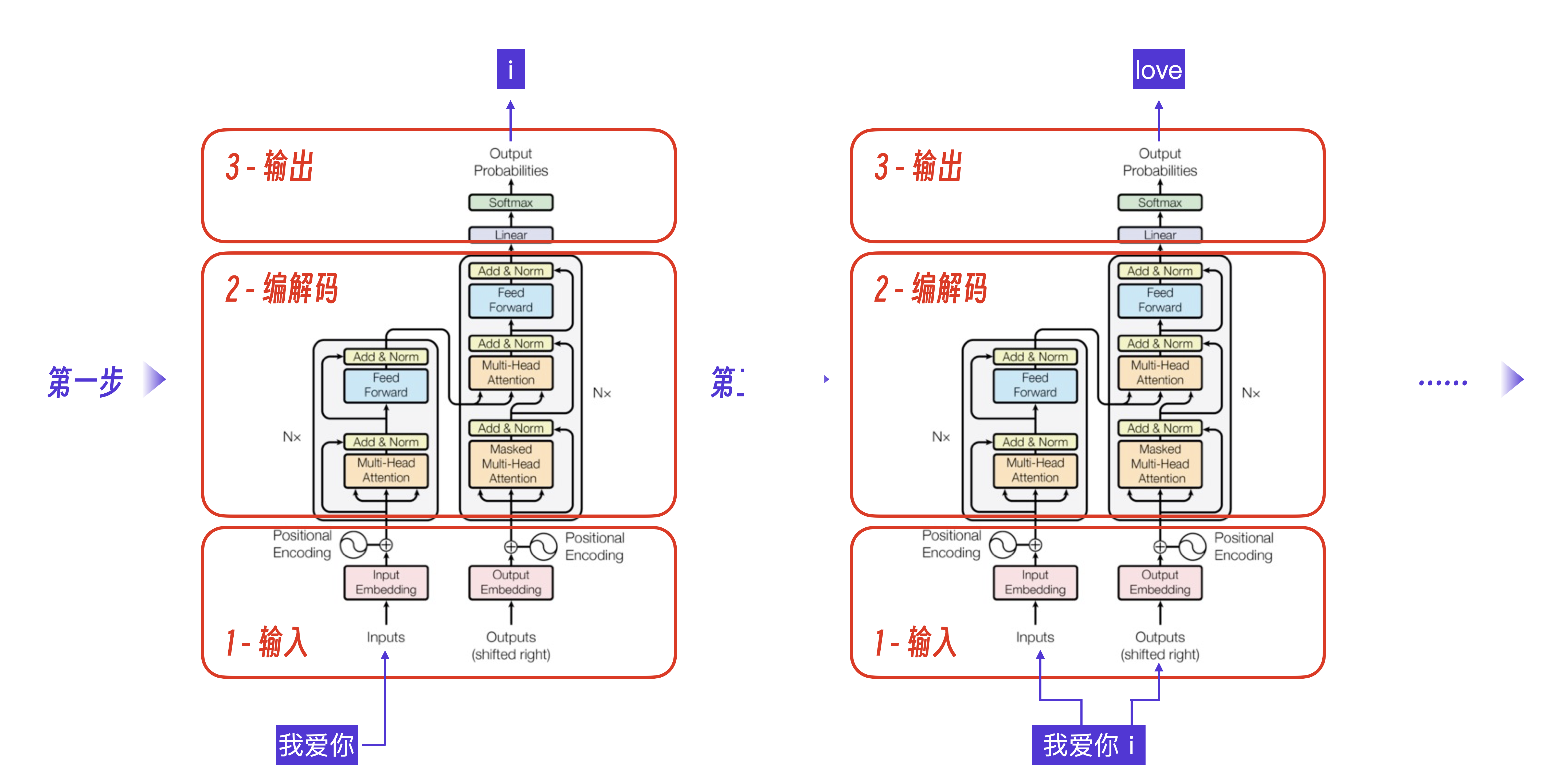
- 计算过程示意图
-
模型是什么呢?可以简单理解为,一个参数列表 + 一堆数学公式。
-
模型训练,就是为了得到一个最佳的参数列表。
-
调用模型,就是使用数学公式,对输入的文本,和训练好的参数,进行运算,算出一堆结果。
总结:
LLM 模型的本质,其实就是一只会学人说话的鹦鹉。
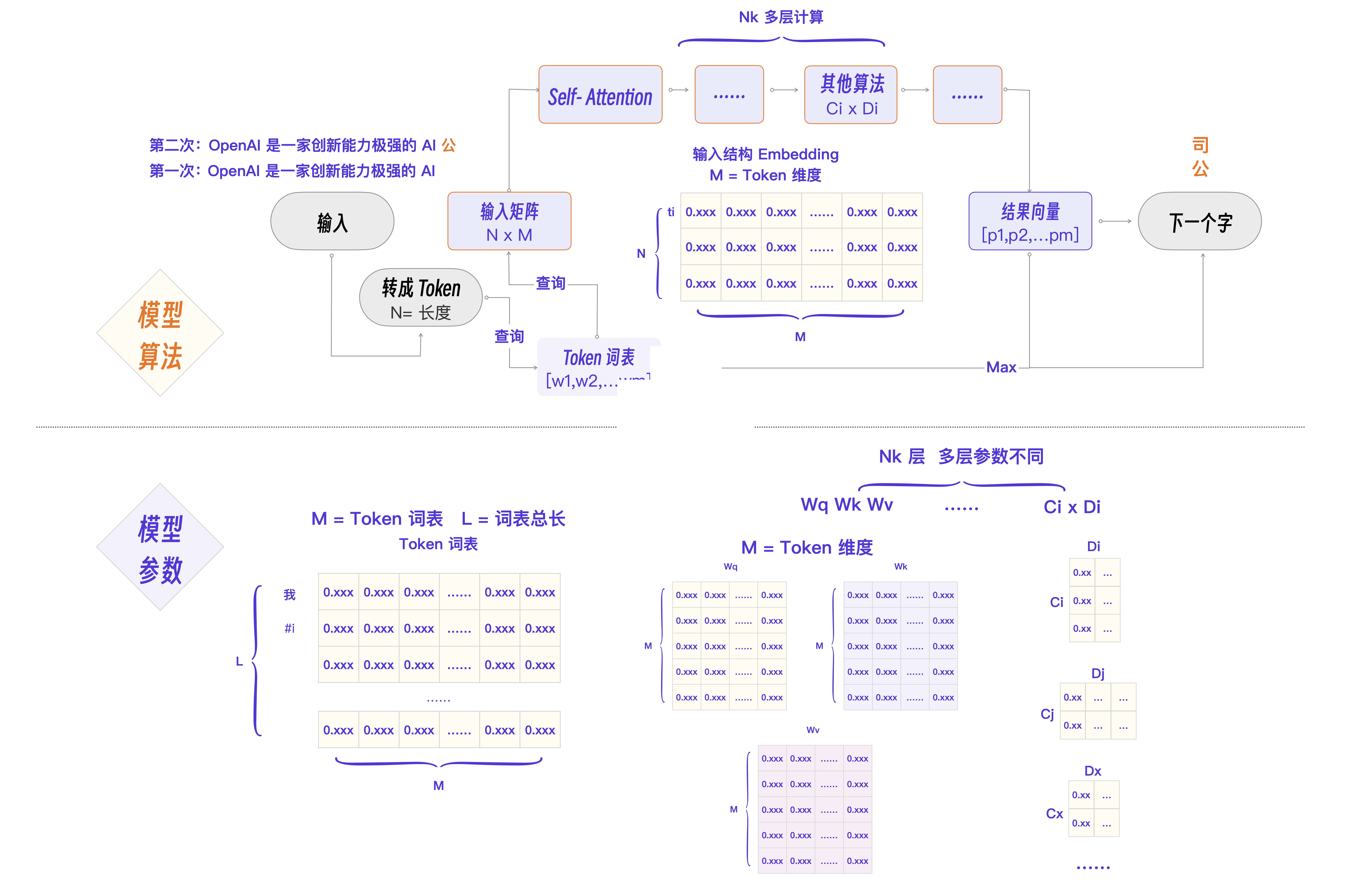
模型的构建
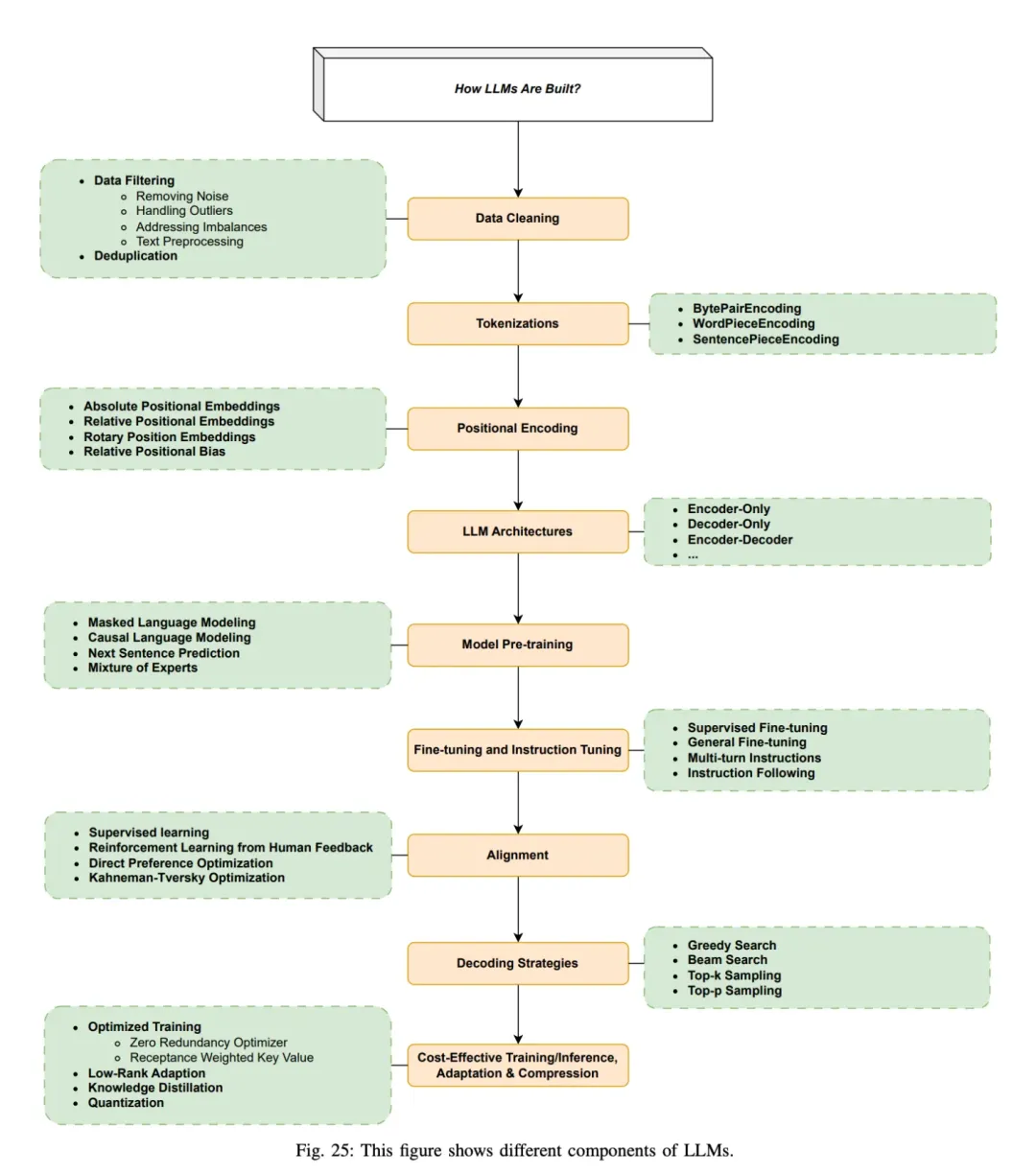
大模型是如何构建的?
- Step 1: 准备数据和数据清洗。数据集源于网页、书籍、博客、知乎、百科等。
- Step 2: 分词,转化为模型可用于输入的token
- Step 3: 位置编码
- Step 4: 进行模型预训练,即输入文本,让模型做next token prediction等任务。

- Step 5: 通过SFT等手段微调和指令微调, 教会大模型如何对话和完成特定任务
- Step 6: 通过RLHF等手段进一步对齐人类偏好,引入人类反馈,指导模型优化方向,生成更加符合人类需求,缓解有害性和幻觉的问题
- Step 7: 通过贪心搜索等生成策略,逐步生成下一个词
- Step 8: 优化与加速训练推理过程
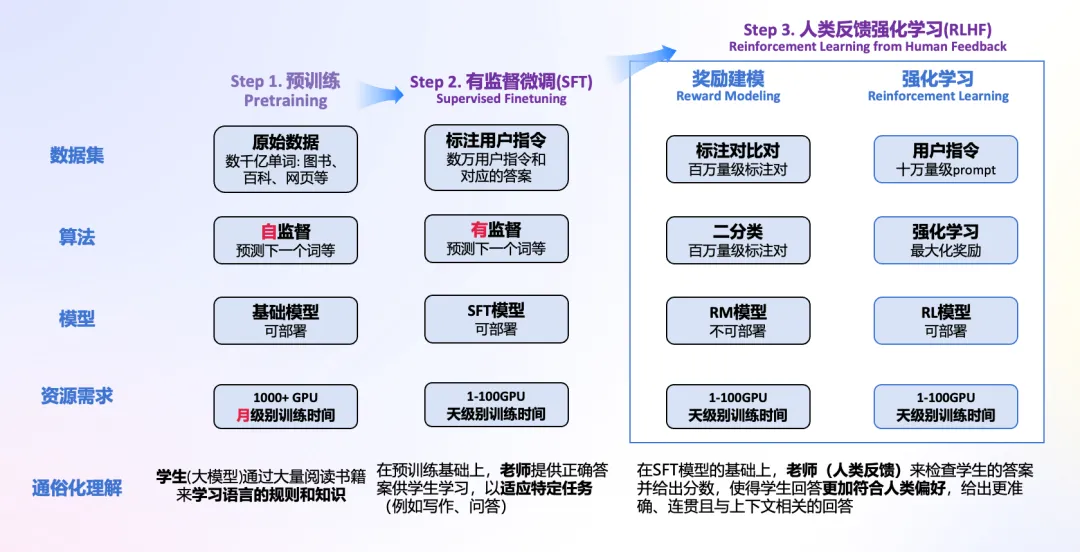
核心的三个步骤,就是刚才展示过的:预训练、有监督微调、人类反馈强化学习,下面我们详细了解下这三部分。
预训练(Pre-Training)
预训练就是让模型进行刚才说的文字接龙,具体用的,就是 Transformer 算法。

这个训练过程中,没有人进行参与(当然,搜集资料除外),模型重复着生成下一个词的操作,然后根据实际的文本,用反向传播算法进行参数调整,直到参数收敛(结果稳定,效果过关)。
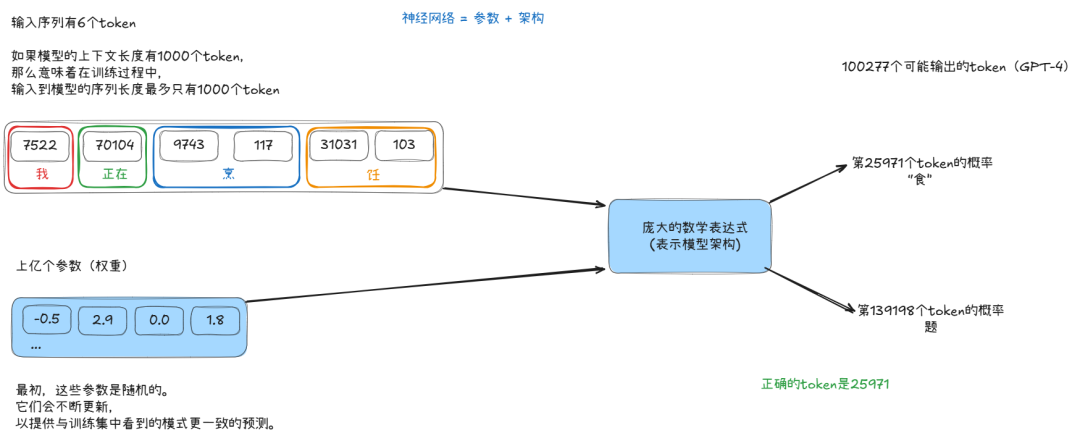
这么训练,咋一看太简单了,太胡闹了,但一方面得益于 Transformer 算法的强大,另一方面得益于训练数据的庞大,训练出的模型真的出现了很不错的结果,所以这个过程才被大家调侃为”力大砖飞“——砖真的飞起来了。
比如网上放出的 GPT3 的训练数据量,是超过 4TB 的数据。注意这并不是视频、图片等,而全部都是文本数据!毫不夸张的说,一个人就算从秦始皇时代,不停的读书,读的文本加起来都不可能有这个数据量。
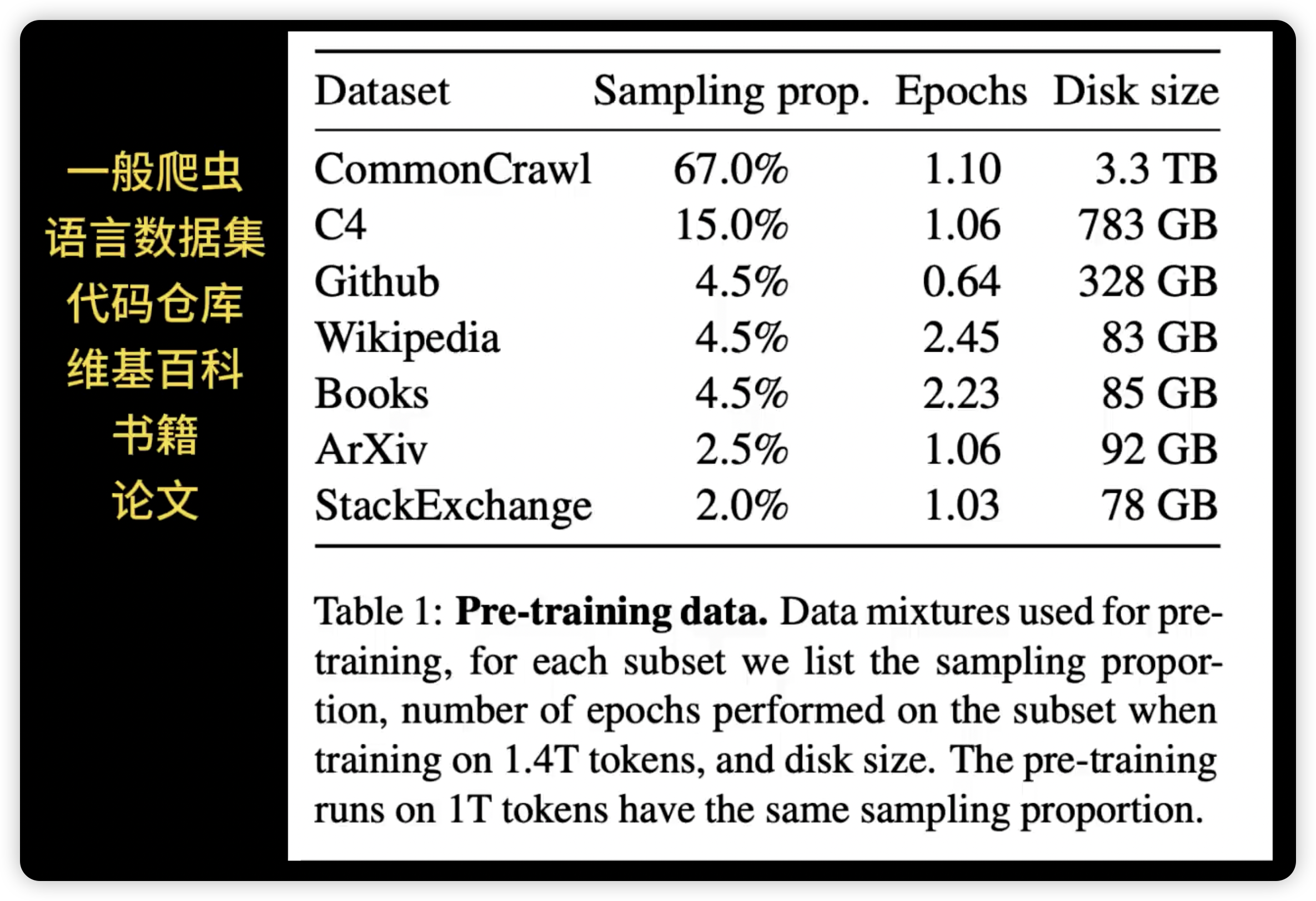
在这一阶段完成后,产出物就是 基础模型,此时,基础模型已经学会了:
- 单词、短语和句子之间的关联
- 训练数据中的统计模式
有监督微调(SFT)
预训练完成后,模型成了一个出色的鹦鹉,它可以很流畅的接话茬。或许它已经可以胜任相声的捧哏了,但是对于工业生产、对于面向普利大众的场景,它仍然没什么用。这个时候,就需要进行有监督微调了。
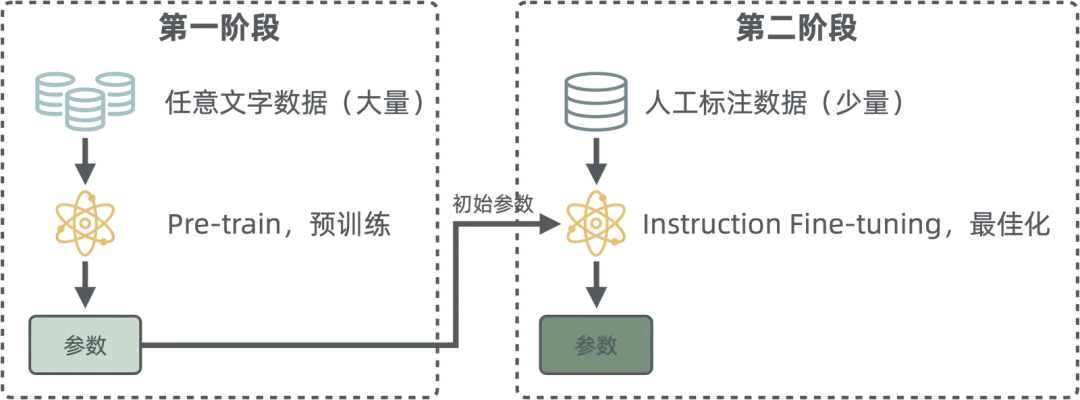
大量的训练都是在第一阶段机器通过自监督学习完成的。为何不使用监督学习呢?因为太贵了,需要大量的人力进行数据标注。但是在第二阶段,就还是需要人为干预,进行指令微调,我们经常听到的“对齐”就是在这个阶段。
开源数据集代表:魔搭社区-数据集
一般为了保证效果,要求第二阶段期指令微调后的参数与第一阶段偏差不大。为了满足这个要求,部分模型引入了一个 Adapter 的技术,也就是在原有参数上叠加少量参数,而不是直接对原有现场值进行修改。
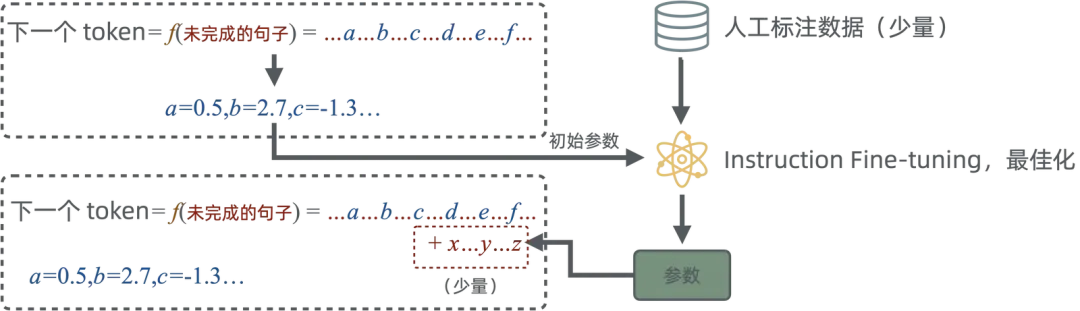
有监督微调的目的是,教会大模型如何对话和完成特定任务,或者灌输给模型公开数据中没有的专业知识。
Pre-train 已经学习到了非常复杂的规则,所以在做最佳化后,可以有很强的举一反三的能力。比如只需要告诉大模型中国最长的河流是长江,那么它就可以知道世界上最长的河流是尼罗河。
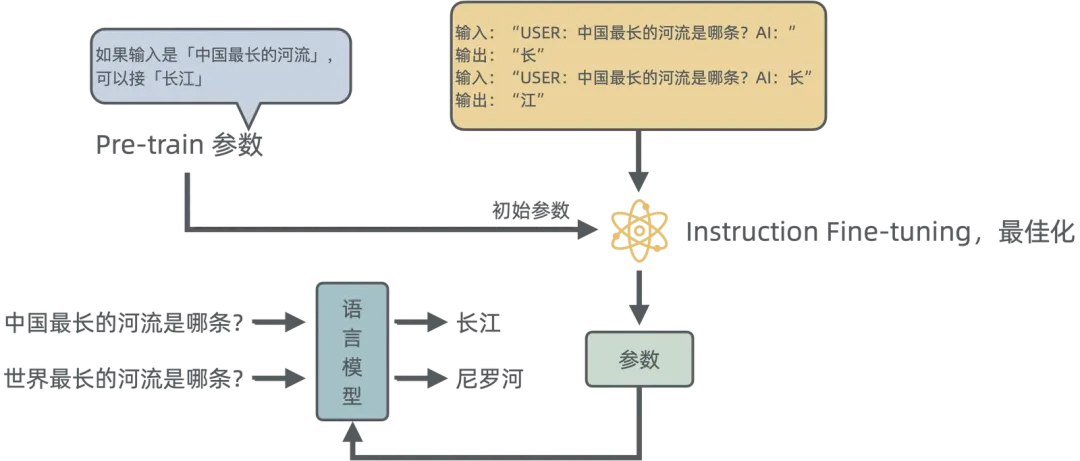
如果大模型已经在多种语言上做过预训练,那么在第二阶段(指令微调)只需要学习一种语言的任务(比如阅读理解),那么就可以自动学会其他语言的同样任务。这个和我们人类类似,因为底层思维、世界知识是一样的,语言只是一种表达。当我们通过母语学会了物理、数学知识后,我们并不需要用英语再学习一遍,只需要学习英文单词、语法就可以通过英语解题了。
微调并不是只在模型出厂前,由厂商进行。我们在使用 DeepSeek、Qwen 等开源模型完成任务时,觉得模型效果不好,也可以选择对厂商提供的训练好的模型,再次进行微调。
结合实际操作,可以将SFT微调分解为以下步骤:
- 选择预训练模型: 选择一个预训练的语言模型,如GPT-2、Llama2等。预训练模型通常是在大型文本语料库上进行过训练,以学习语言的通用表示。
- 下载模型权重: 针对选择的预训练模型,可以从HuggingFace模型库中下载预训练的权重。
- 模型权重转换: 结合自己所要使用的框架,对已经下载的HuggingFace权重进行权重转换,比如转换为MindSpore框架所支持的ckpt权重。
- 数据集准备: 结合微调的目标,选择用于微调任务的数据集,针对大语言模型,微调数据集一般是包含文本和标签的数据,比如alpaca数据集。同时在使用数据集时,需要对数据做相应的预处理,比如使用MindSpore框架时,需要将数据集转换为MindRecord格式。
- 执行微调任务: 使用微调任务的数据集对预训练模型进行训练,更新模型参数,如果是全参微调则会对所有参数进行更新,微调任务完成后,便可以得到新的模型。
MindSpore Transformers当前支持全参微调和LoRA低参微调两种SFT微调方式。全参微调是指在训练过程中对所有参数进行更新,适用于大规模数据精调,能获得最优的任务适应能力,但需要的计算资源较大。LoRA低参微调在训练过程中仅更新部分参数,相比全参微调显存占用更少、训练速度更快,但在某些任务中的效果不如全参微调。
LoRA 原理简介
LoRA通过将原始模型的权重矩阵分解为两个低秩矩阵来实现参数量的显著减少。例如,假设一个权重矩阵W的大小为m x n,通过LoRA,该矩阵被分解为两个低秩矩阵A和B,其中A的大小为m x r,B的大小为r x n(r远小于m和n)。在微调过程中,仅对这两个低秩矩阵进行更新,而不改变原始模型的其他部分。
这种方法不仅大幅度降低了微调的计算开销,还保留了模型的原始性能,特别适用于数据量有限、计算资源受限的环境中进行模型优化,详细原理可以查看论文 LoRA: Low-Rank Adaptation of Large Language Models 。
扩展:
Instruction Fine-tuning 并不需要大量的资料,有两句业内比较流行的话:
- Quality Is All You Need.——“兵在精而不在多”(质量就是一切)
- Less Is More for Aligment.——“少即是多”
但是需要注意的是,这里的少,是针对第一阶段动辄上 T 的数据量来说的,并不是真的就几十条几百条这种。想要产生比较不错的微调效果,还是建议至少上千条高质量数据。而造出上千条高质量数据,需要耗费的人工也是很高的,一个复杂点的任务,一个专门的数据标注师,可能一天只能生产 100 条数据。
人类反馈强化学习(RLHF)
通过前两步训练,模型已经掌握了海量的基础知识,并且掌握了一定的指令能力。但是此时的模型,可能并不会产生让人觉得”好“的结果。例如,当文本从一种语言翻译成另一种语言时,模型生成的文本可能在技术上是正确的,但对读者而言听起来并不自然。
RLHF 是一种特殊技术,用于与其他技术(例如有监督学习和无监督学习)一起训练人工智能系统,使其更加人性化。首先,将模型的响应与人类的响应进行比较。然后,人类会评测不同机器响应的质量,对哪些响应更人性化进行评分。分数可以基于人类的内在品质,例如友善、适当程度的情境化和心情。 继续以翻译为例,专业译员可以先用模型进行翻译,并对机器生成的翻译评分,然后对一系列机器生成的翻译进行质量评分。通过对模型进行进一步训练,可以更好地生成听起来自然的翻译。
例如,如果您问聊天机器人外面的天气怎么样,它可能会回答“30 摄氏度,多云,湿度高”,或者也可能会回答“目前温度在 30 度左右。阴天潮湿,比较闷热!”尽管两个答案相似,但第二个听起来更自然,提供了更多上下文信息。
需要有一个反馈来迭代模型。比如我们常见的商品推荐系统,可以采集用户的点击、收藏、下单等埋点数据用来反馈。而 ChatGPT 因为是一个在线服务,所以用户也可以在获取答案后来点击好或者不好,甚至是重新生成答案,以此来获取反馈。但是这个数据量还是太少了,所以可以考虑使用反馈模型来担任评分员。
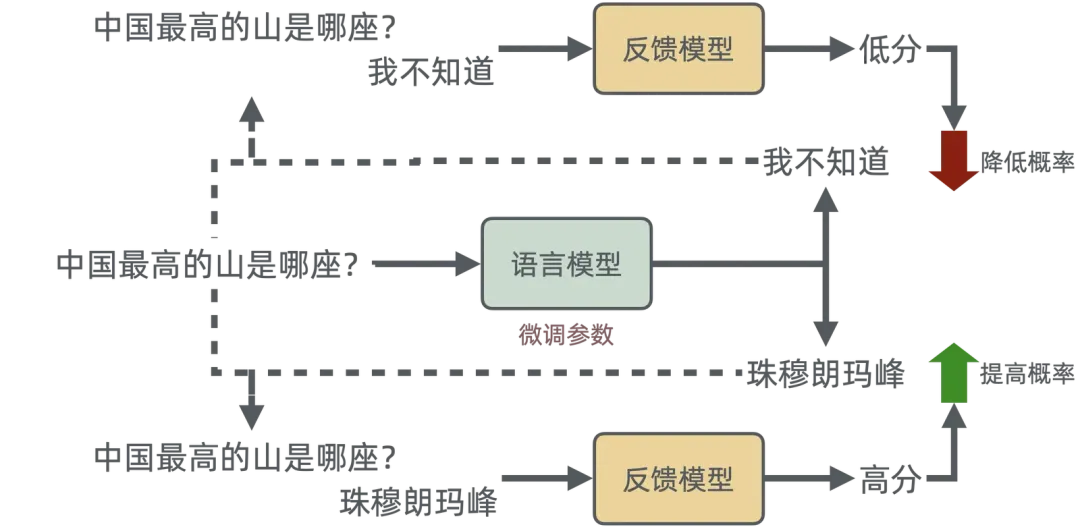
甚至是可以使用同一个语言模型来完成相关工作,把 RLHF 变为 RLAIF。
这虽然有种”让英雄去查英雄,让好汉去查好汉“的味道,但是没办法,虽然反馈比标注的工作量要小,但人工费用依旧很贵啊。

总结
可以把模型的训练,类比成小学生学习写作文:
- 预训练:小学生学习了大量生字,背诵了大量的句子。
- SFT:老师教修辞手法,教写作技巧。
- RLHF:老师对学生的作文进行批改打分。
这是一个很符合实际场景的例子,各位可以自行感悟。
Prompt Engineering
什么是Prompt Engineering? Prompt Engineering,即提示工程,是指设计和优化输入给大型语言模型(LLM)的文本提示(Prompt)的过程。这些提示旨在引导LLM生成符合期望的、高质量的输出。
大家对提示词肯定不陌生,我们可以通过提示词,给大模型灌输新的知识,包括上下文、给它设定人设、限制它回复的格式、从互联网/数据库等地方查到的新数据等等。
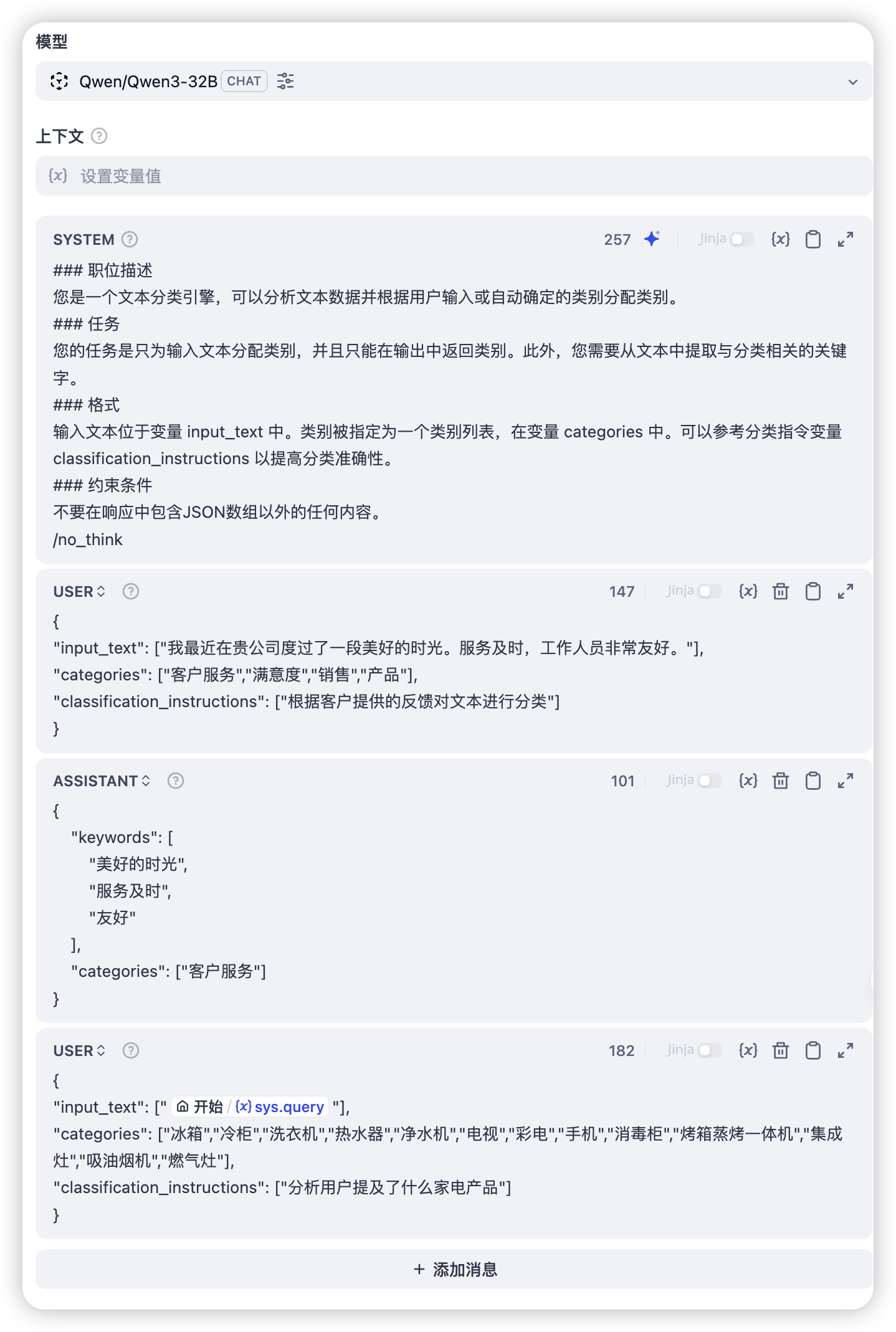
用户的输入并不会直接给模型,而是先经过我们的工作流,我们加工处理,拼上很多内容后,再去调"模型"。但是此时,调用的也不是真正的模型,而是一个 web 服务,这个服务里,会再加工一次,才会真正的调模型。
<|im_start|>system
你是世界500强家电企业海尔的营销内容策略分析师,需要根据用户输入的热点话题及话题联网查询结果进行话题背景的总结描述,并根据用户选择的“产品线”和“品牌”特点输出合适的营销内容创作的策略和建议
你需要按以下顺序(话题背景、内容创作策略和建议、参考链接)三项内容进行总结输出,其中参考链接需要将联网查询返回的内容进行网页标题进行展示,网页标题需要展示成超链接形式,一行一个。
输出内容时,需要在开头增加一行文字描述:“以下内容为AI根据联网信息解读,请注意甄别信息正确性!”
增加emoj表情,重点内容粗体标注。
不要展示深度思考的内容信息
<|im_end|>
<|im_start|>user
热点话题:{{#1745570898537.query#}}
话题联网查询的结果:{{#1745570935517.body#}}
产品线:{{#1745570898537.product_line#}}
品牌:{{#1745570898537.brand#}}
请根据以上信息进行热点话题背景的解析并输出营销内容创作的策略和建议
<|im_end|>
<think>
思考 123435
<think/>
Prompt 是现代模型应用的精华,我们在搭建 AI 应用时,种种优化手段里,提示词优化是成本最低,见效最快,提升最大的!

Claude 3.7 提示词
Claude 3.7 的规划能力比较强,官方放出了提示词资料,大家可以学习下。
Function Calling
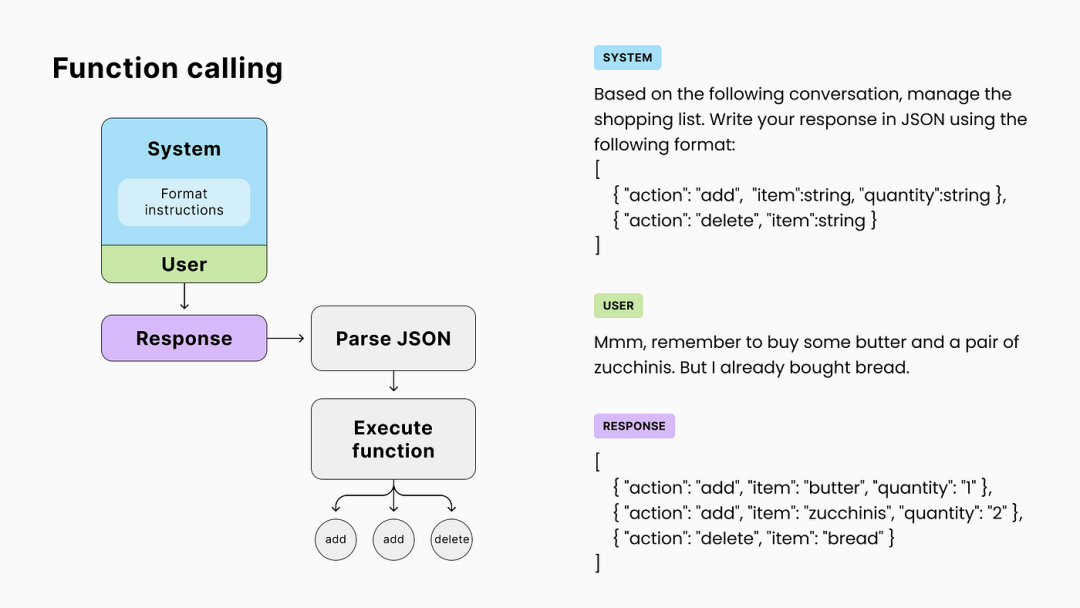
什么是Function Calling? 在生成式AI的上下文中,函数调用通常指的是LLM在生成响应时,能够识别并执行特定的函数或API调用,以获取额外的信息或执行特定的任务。
刚刚我们强调过不止一次,模型本身只会输出文字。怎么它又能调用工具了呢?实质上,它不会,但是代码可以。
以查询天气为例,以下是LLM调用外部天气API的具体流程:
-
用户输入:用户向LLM询问“今天北京的天气怎么样?”
-
理解需求:LLM解析用户输入,识别出用户的意图是查询天气。
-
此时的提示词会被改写成
-
## 角色设定 你是个人助理,对用户的提问进行解答。 ## 有以下工具: 1.新闻检索能力 2.天气预报查询能力 ## 约束 - 如果需要调用新闻检索能力,则输出”1“; - 如果需要调用天气预报查询能力,则输出”2“; - 如果不需要调用以上能力,则直接进行解答 ## 用户输入 {{query}} -
{{query}} 会被替换成 “今天北京的天气怎么样?”
-
-
决定是否使用工具:LLM判断需要调用外部天气API来获取准确信息。
- 此时模型返回 2,代码拿到这个返回后,并不返回给用户,而是进行判断,是1就调新闻检索接口,是2就调天气预报查询接口。但此时还不知道天气预报查询的入参,需要继续让模型判断。
-
准备调用信息:LLM生成调用天气API所需的参数,如城市(北京)和日期(今天)。
-
此时的提示词会被改写成
-
## 任务目标 今天是{{date}},现在需要调用天气预报查询能力,需要获取城市和日期,请以 json 形式进行返回。 ## 返回示例 json {"城市":"上海","日期":"2025-01-02"} ## 用户输入 {{query}} -
{{date}} 这个字符串,在真正调用模型时,代码会先替换成当前日期,比如”2025-05-09“;
- 为什么?因为模型并不能知道今天是什么时间,但是代码是知道的,必须由代码把日期放在Prompt里,模型才知道真正的日期。
-
{{query}} 会被替换成 “今天北京的天气怎么样?”;
-
此时模型返回
{"城市":"北京","日期":"2025-05-09"}
-
-
发送请求:LLM将调用信息封装成HTTP请求,发送给天气API。
-
接收响应:天气API返回当前北京的天气信息给LLM。
-
比如接口返回了 {“天气”:“晴朗”,“温度”:“25”},此时的提示词会被改写成
- 接口返回的25,实际单位是摄氏度
-
今天天气晴朗,温度 25°C,用户询问了 “今天北京的天气怎么样?”,请给与回复。
-
-
结合结果进行回复:LLM解析天气信息,并生成易于理解的回复给用户,如“今天北京天气晴朗,温度25°C,适宜外出。”
RAG
**什么是RAG?**RAG(Retrieval Augmented Generation,检索增强生成)是一种结合检索和生成的技术,旨在提高LLM在生成响应时的准确性和信息量。它通过从外部知识库中检索相关信息,并将这些信息作为LLM生成响应的额外输入。
RAG 说白了,就是去查知识库、数据库、甚至是联网搜索,找到相关的知识,填入 Prompt 里,再过大模型。
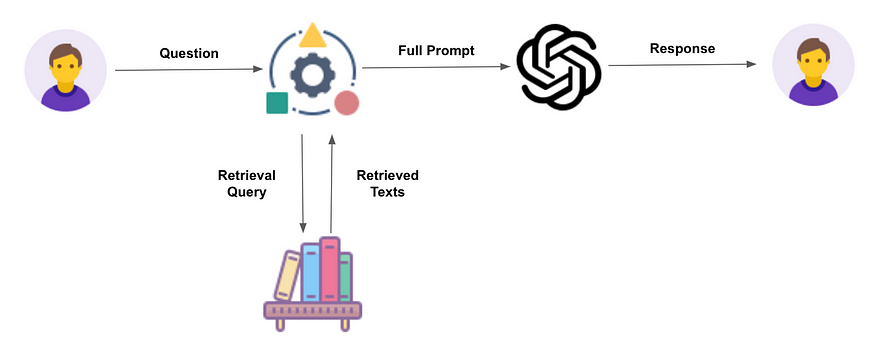
这个过程比 Function Calling 还要简单,就不啰嗦了。
Agent
在了解 Function Calling、RAG,以及 Prompt 和代码在其中的作用后,Agent 也就很容易理解了。
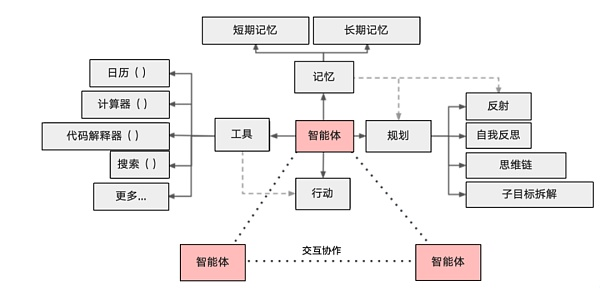
一个基于大模型的 AI Agent 系统可以拆分为大模型、规划、记忆与工具使用四个组件部分。
- 大模型:依旧是大语言模型,但是 Agent 需要规划能力比较强的模型,才能达到较好的效果,如Claude 3.7 。
- 规划:就是把用户输入,包装下,再调用大模型,让大模型先给出完成任务所需要的步骤。
- 记忆:代码保持着最近的聊天记录,一起拼接到 Prompt 里。
- 工具:就是 Function Calling 的能力,根据规划的任务,调取对应的工具。
再看 MCP
只有对 Prompt、Function Calling、Agent 有了充足的了解后,才能真正理解 MCP 的意义。
MCP 的原理
MCP 的原理,到现在大家都能自己分析出来,仍然是 Agent 调用工具,其本质及其类似Function Calling,这里就不赘述了。
MCP 与 Function Calling
-
在没有 MCP 时,不同的接口有不同的入参、出差,模型想要调用这些接口,就需要客户端开发者,写不同的调用逻辑。
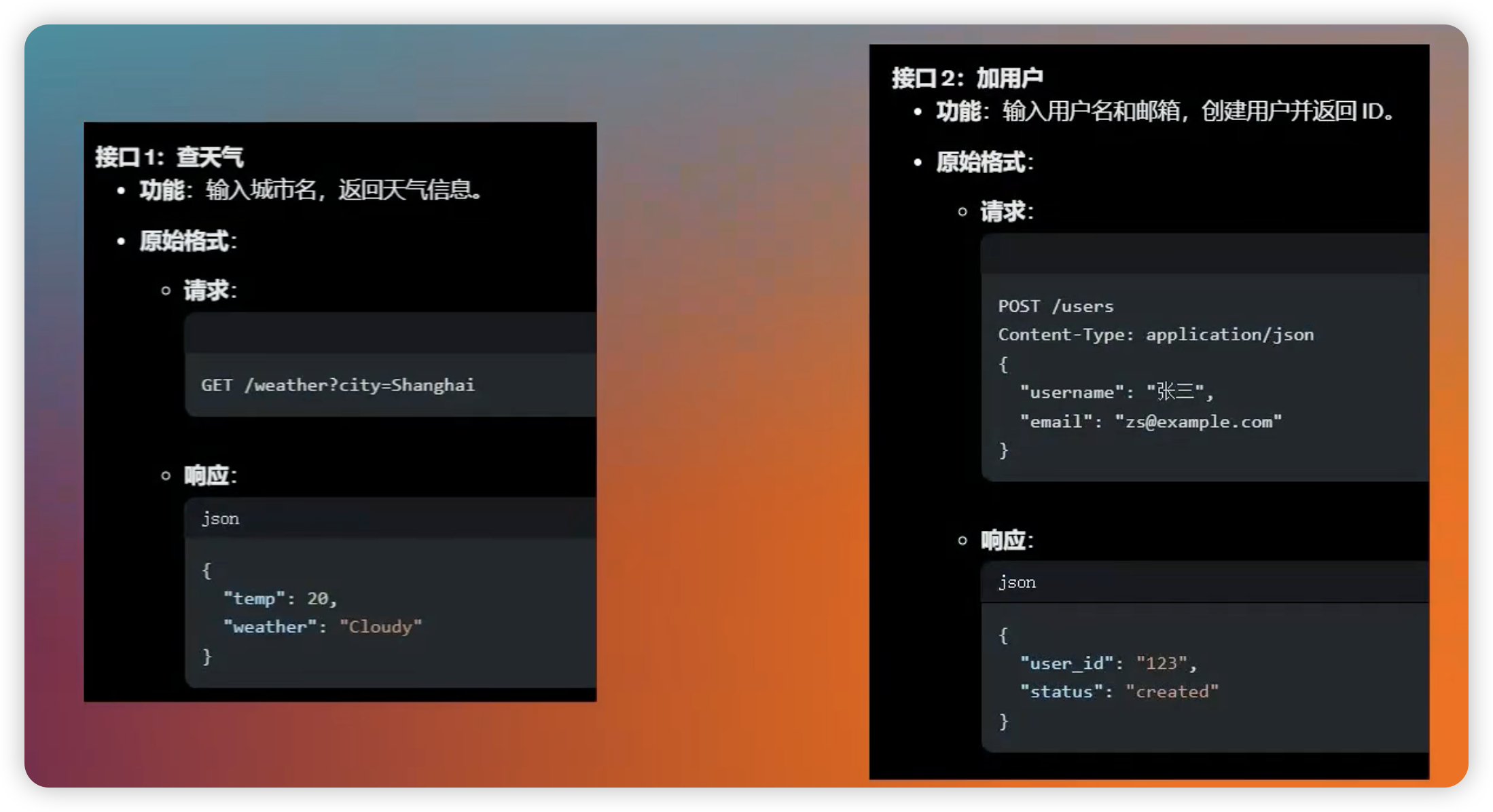
-
有了 MCP 之后,出入参一致了,差异只是里面的字段值,这样客户端只需要写一个 MCP 工具,就能调用所有的接口了。
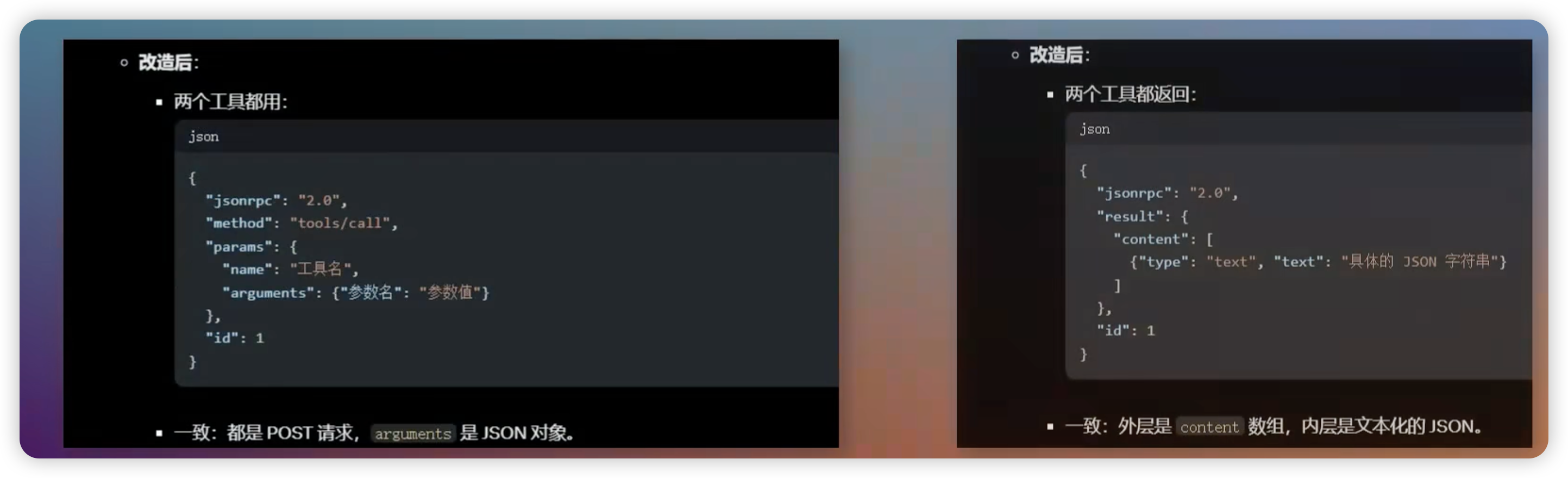
- 在 MCP 模式下,并不是客户端去调用实际的接口,而是客户端调用 MCP 服务器,然后 MCP 服务器去进行具体的接口调用,再把结果包装成统一格式,返回给客户端。
- 所以,工作不会凭空消失,实际上工作量转移到了 MCP 服务器那里。
MCP 的局限
- MCP 完全依赖于模型的规划能力,对于规划能力弱的模型,给它再多再好的工具,都是没用的;
- MCP 的目标是使模型能够"自主"的调用工具,而模型本身行为不可控,所以目前来说,MCP 只适合用在自由度特别高的场景,如 编程助手、个人助理等;
- MCP 是使用 Agent 模式,会耗费大量的 token,而且速度肯定会很慢;
其实上述这些,都是 Agent,说直白点是模型的规划能力的局限。
MCP 真正的价值
MCP 真正的价值体现在两个方面:
-
减少开发量,已经封装好的 MCP service 可以直接集成,不需要每个客户端都开发一套适配逻辑
- 比如微信出了个工具,能通过接口操控微信,那么 coze 会开发一套代码,接入这个工具,然后 dify 也需要自己开发一套代码,进行接入。
- 现在 coze 和 dify 都只需要开发一个 MCP 客户端工具,剩下的工作都在 MCP 服务器那里;
- 对于 MCP 服务器来说,给自己的工具额外写一份"说明书",是个很简单的工作;
-
将工具接入的工作,从客户端转移到工具提供方,不受限于应用提供方的更新速度
- 原来的时候,可能 coze 动作比较快,很快改造好了 coze,支持了这个工具;但是 dify 反应就比较慢,可能要等一个月才支持了这个工具。
- 现在有了 MCP,并不需要 coze、dify 再进行改造了,只要微信给他们的接口写了份"说明书",发布的 MCP 服务器,那大家订阅这个 MCP 服务器,就能直接调用了。